Now, if you’re a data professional with little interest in Eurovision, we’re grateful, frankly, that you’ve stuck with us. Maybe we’ve converted you along the way.
But let’s bring this back to the real world, or at least your world.
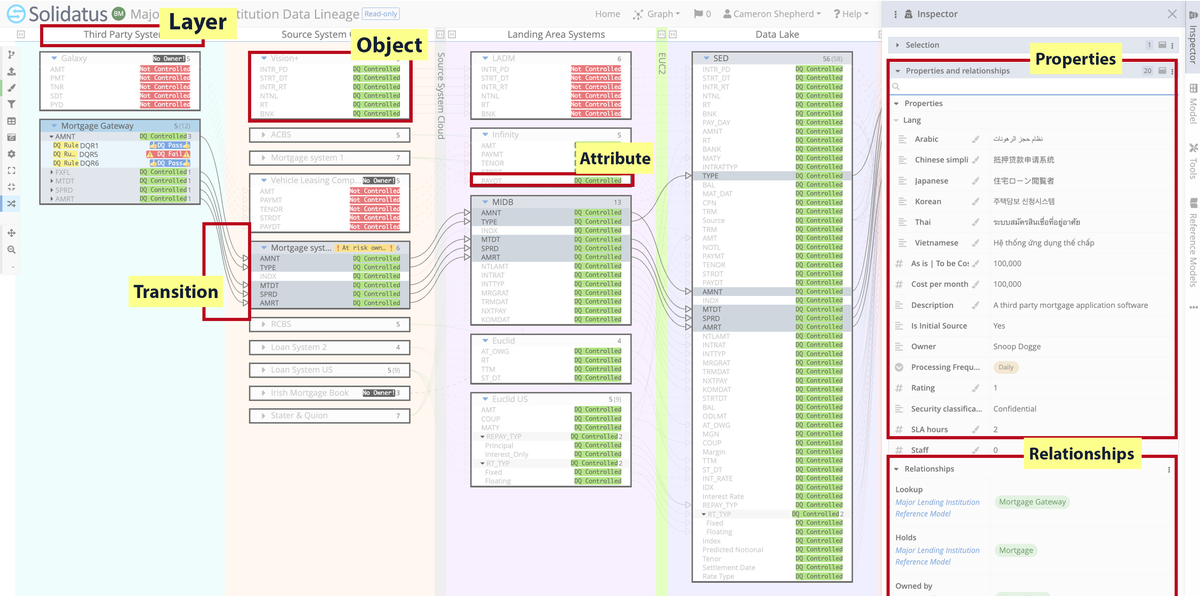
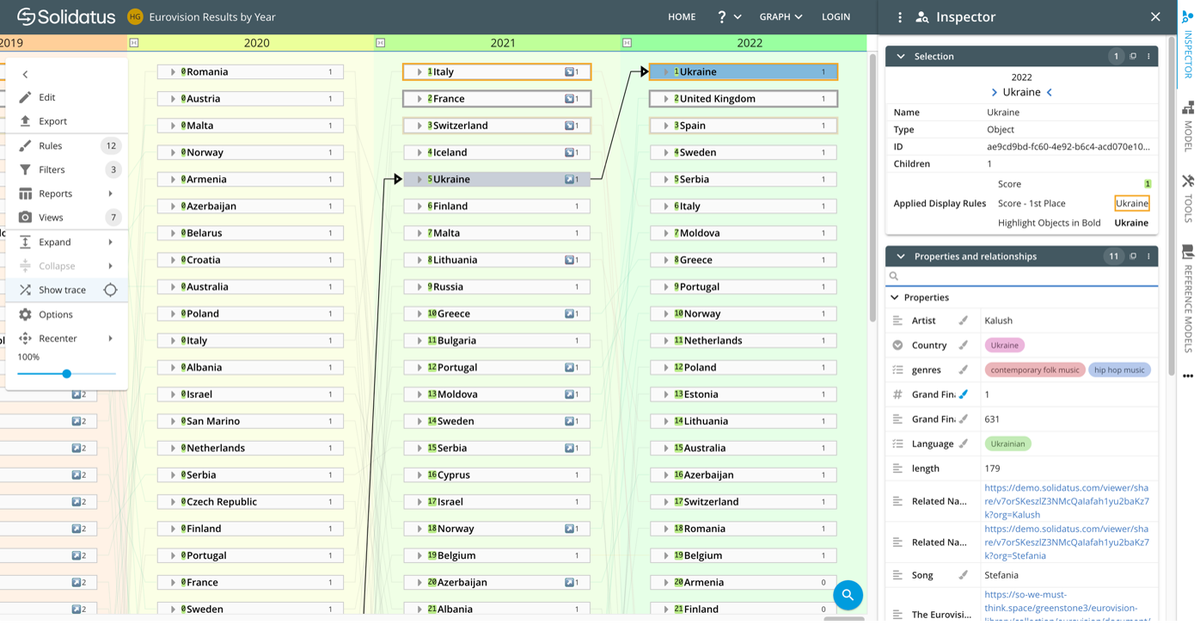
The beauty of a visualization tool like Solidatus is that there are virtually no limits to the applications its graph technology can be put to, all of it exploiting and promoting active metadata.
We have, though, found that Solidatus particularly lends itself to these solutions: governance and regulatory compliance; data risk and controls; data sharing; business integration; and environmental, social and governance (ESG).
We’re going to end with a quick review of governance and regulatory compliance.
Using Solidatus, you create living blueprints that map how your data flows – a.k.a. lineage – as it moves through your systems – both now and at other points in time. You can connect your data to the processes that create it, to the policies that guide it, and to the obligations that regulate it. With this framework in place, you can maintain transparency across your business, meet ever-evolving regulatory requirements, and accelerate change programs.
That’s the boilerplate. But what does it mean in practice?
Well, let’s finish with a few excerpts from our recently published case study, Solidatus models HSBC’s global lending book (PDF), this use case – alongside many others, including business integrations, and data risks and controls – being a key component of their several objectives.
In under six months, a team of two was able to document and model the global bank’s entire credit and lending book, demonstrating traceability from source to consumption. They now have a highly scalable and automated solution that is being applied to several applications from ESG to liquidity calculations and other regulatory uses.
Do read the case study (PDF) to see how they reduced a project’s cost from $5,000,000 to under $500,000, a saving of more than 90%.
And don’t let inefficient data management practices be your Waterloo.